Today’s tutorial is on how to merge multiple datasets using the Pandas library in python. We will add new columns based on a key column, and we will also aggregate information for the same column names from various datasets.
I have made five sample datasets (A1.csv, A2.csv, A3.csv, A4.csv, A5.csv) that we will be merging.
The code and the data can be found in this GitHub repository. I have organized the five datasets in this “to-merge” folder.
Each dataset contains
- an ID column (key column on which we will be merging different datasets)
- unique columns (other datasets don’t have that column)
- common columns (other datasets have that column as well but may contain different information)
See the figure below for what A1.csv looks like.

For this tutorial, you will need Pandas library installed.
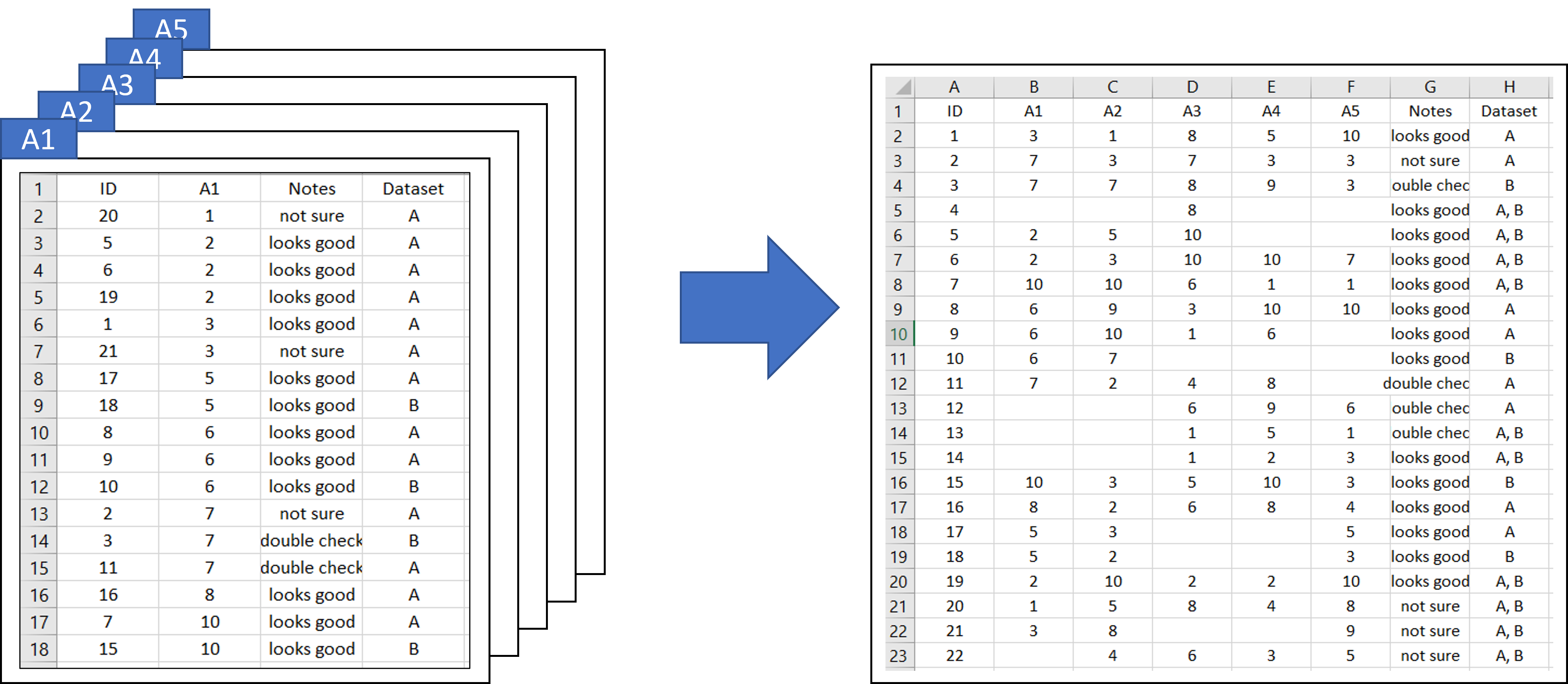
Below are the screenshots from the five sample datasets. We really want to combine A1, A2, A3, A4 and A5 columns (red) based on the ID column (blue). We don’t quite care for other columns which are “Notes” and “Dataset”, but we will still retain them. These additional columns may contain different information, so in those cases, we will merge their information together by a comma. Also, note that the datasets are of different lengths, i.e., each has a different number of rows; some contain 17 rows, some 18, and so on.

The expected result after merging the five datasets would look like below.

I hope I made the problem statement clear. Now, let’s get to coding.
First, import the libraries that we need.
import pandas as pd
import osNow, let’s get to the folder and see what files are there.
folder = "to-merge"
print(os.listdir(folder))['A1.csv', 'A2.csv', 'A3.csv', 'A4.csv', 'A5.csv', 'expected_result.csv']
We have five individual files to merge (‘A1.csv’, ‘A2.csv’, ‘A3.csv’, ‘A4.csv’, ‘A5.csv’) and a file called ‘expected_result.csv’. The later is self-explanatory, and we will compare that to our outcome at the end of the tutorial. It’s always good practice to test the code with small sample files to ensure it works.
Let’s get a list of the files to merge and store it in ‘files_to_merge’ variable.
files_to_merge = [i for i in os.listdir(folder) if 'A' in i]Feel free to peak at the files; well uhh, let’s do that.
df_sample = pd.read_csv(os.path.join(folder, files_to_merge[0]))
df_sample
Okay, so let’s figure out what to do next. One way is to merge the files all into one big file simply on the key column which is the “ID” column. We will have multiple columns that will look kind of duplicated but we will deal with them later.
We will set df_original to contain the first file (which is index 0 in files_to_merge), and we will keep adding the other files to the df_original. Since we want to merge them on the key column ‘ID’, set ‘ID’ to ‘on’ parameter in the merge function. We will do ‘outer’ joining because we want to contain all the rows from both the left and right data frames.
Note that when we are looping through the files, we don’t need to cover the first one, since it’s the data frame to which we are adding the rest. So, during the for loop, we will go from index 1 of files_to_merge to the rest.
df_original = pd.read_csv(os.path.join(folder, files_to_merge[0]))
for i in range(len(files_to_merge[1:])):
df = pd.read_csv(os.path.join(folder, files_to_merge[i+1]))
df_original = pd.merge(df_original, df, on='ID', how = 'outer')
print(df.shape)Now, let’s see what the df_original looks like.
df_original
It’s looking a bit messy with all the kinda-sorta duplicated columns, but we will deal with them. Let’s gather all the Notes columns and Dataset columns.
notes_cols = [j for j in df_original.columns if 'Notes' in j]
dataset_cols = [j for j in df_original.columns if 'Dataset' in j]
print(notes_cols, dataset_cols)['Notes_x', 'Notes_y', 'Notes_x', 'Notes_y', 'Notes'] ['Dataset_x', 'Dataset_y', 'Dataset_x', 'Dataset_y', 'Dataset']
We will merge all the ‘Notes_x’ and ‘Notes_y’ columns into ‘Notes’ column. We will merge all the ‘Dataset_x’ and ‘Dataset_y’ columns into ‘Dataset’ column.
Note that we can easily drop these columns if they are identical duplicates, but in this case, they aren’t. Some (esp. Dataset column) may have different information and we will keep all the available info.
df_original['Notes'] = df_original[notes_cols].apply(
lambda x: ', '.join(x.dropna().astype(str)),
axis=1
)
df_original['Dataset'] = df_original[dataset_cols].apply(
lambda x: ', '.join(x.dropna().astype(str)),
axis=1
)Let’s look at what ‘Notes’ and ‘Dataset’ columns contain now.

They contain a lot of redundant content which we will deal with. We will remove all the exact duplicates or redundancies in each row, so we write this small function.
def remove_duplicate_strings(sample):
list_strings = sample.split(', ')
unique_strings = list(set(list_strings))
unique_strings.sort()
return ', '.join(unique_strings)This function will take a string, split them by ‘, ‘, remove all the duplicates and sort the values. In the end, it returns a string containing just the unique values separate by ‘, ‘.
You can test the function and see if it works well.

Now, let’s apply that function to ‘Notes’ and ‘Dataset’ columns.
cols_to_address = ['Notes', 'Dataset']
for i in cols_to_address:
df_original[i] = df_original[i].apply(remove_duplicate_strings)Now, we will see the updated ‘Notes’ and ‘Dataset’ columns.

Now that it’s sorted out, let’s drop the columns that we no longer need.
cols_to_drop = [i for i in notes_cols + dataset_cols if '_' in i]
df_original = df_original.drop(columns=cols_to_drop)
df_original
It’s looking good and almost done. Let’s improve it by addressing a couple of minor things and then we can export the merged dataset. We will replace NaNs with empty strings.
df_original.fillna('', inplace=True)
We will then sort the dataset by IDs, and remove the indices.
df_original = df_original.sort_values(by='ID', ascending=True)
df_original.reset_index(drop=True, inplace=True)
df_original
Alright, now it’s export-ready. But before that, remember we had an expected result file (expected_result.csv)? Now, we can compare our result data frame to that expected data frame and see if we did it right.
So, let’s load that ‘expected_result.csv‘ file, fill NaNs with empty strings, and sort the data frame by ‘ID’ column.
df_expected = pd.read_csv(os.path.join(folder, 'expected_result.csv'))
df_expected.fillna('', inplace=True)
df_expected.sort_values(by='ID', ascending=True, inplace=True)
Now, let’s compare our result data frame with the expected data frame.

Cool! They match and our goal here is successfully completed!
Now, let’s export our result file to csv.
df_original.to_csv('resulting_merged_data.csv', index=False)Alright, we are now coming to the end of this blog post. As always, I thank you for visiting my blog and welcome constructive feedback. Please let me know if you detect any mistakes as well.